

Ludger von Döllen
Wie vermeidet man es Daten auszuwerten, die nicht die Realität widerspiegeln oder unzuverlässig sind? Gibt es Methoden, um schlechte Datenqualität früh zu erkennen und zu beheben?
Häufige Ursachen für schlechte Datenqualität sind Fehler bei manueller Dateneingabe und Änderungen von Programmcodes.
Codeanpassungen können unerwartete Seiteneffekte haben, also andere Programmlogiken beeinflussen, die nicht im Fokus des Entwicklers waren. Bereits erfolgreich getestete Logiken führen plötzlich nicht mehr zu den erwarteten Werten. Wie stark sich eine schlechte Datenqualität auswirkt, hängt auch davon ab wie schnell sie erkannt wird. Es kann sein, dass die Verzerrung so groß ist, dass unplausible Ergebnisse auffallen bevor sie an Dritte kommuniziert werden (der Umsatz hat sich vervielfacht, Zahlen des aktuellen Tages fehlen etc.). Dennoch kann in diesem Fall bis zur Behebung des Fehlers, die gewünschte Information zunächst einmal nicht bereitgestellt werden. Die Korrektur des Fehlers kann sehr teuer werden.
Ausserdem werden mittlerweile viele Berichte mit Hilfe von Business Intelligence-Lösungen automatisiert zugestellt, so dass eine redaktionelle Prüfung in diesen Fällen nicht erfolgt. Erhalten Berichtsempfänger falsche Ergebnisse, droht ein Vertrauensverlust in die Business Intelligence-Anwendung.
Bleiben Fehler völlig unerkannt, kann dies zur Fehlsteuerung von Unternehmensprozessen führen.
Um eine schlechte Datenqualität zu erkennen benötigt man einen Referenzwert, mit dem man sein aktuelles Ergebnis prüfen kann. Referenzwerte können sein:

Um manuellen Aufwand für die Prüfung zu vermeiden, verwenden wir eine Methode, welche die Prüfung automatisch und regelmäßig durchführt.
Umsetzungsbeispiel
Das folgende Beispiel zeigt die Überprüfung der Umsatzwerte eines abgeschlossenen Geschäftsjahres. Umsätze dürfen sich nachträglich nicht ändern!
1. Schritt: “Testfall” anlegen und beschreiben
| TESTFALL_ID | NAME | BESCHREIBUNG | DATENTYP | AKTIV_JN |
|---|---|---|---|---|
| Vertrieb_GJ_2021 | Vertriebsdaten Geschäftsjahr 2021 | Überprüfung der Vertriebsdaten für das Geschäftsjahr 2021 | ZAHL | J |
| … | … | … | … | … |
2. Schritt: „Kriterien“ hinterlegen
Da in diesem Fall der berechnete Wert dem Referenzwert entsprechen soll, wird ein Gleichzeichen als Operator hinterlegt.
| TESTFALL_ID | OPERATOR | ERLAUBTE_ABWEICHUNG_PROZENT | ERLAUBTE_ABWEICHUNG_ABSOLUT | AKTIV_JN |
|---|---|---|---|---|
| Vertrieb_GJ_2021 | = | 0 | 0 | J |
| … | … (<, >, <=, >=) | … % | … | … |
3. Schritt: „Werte“ bereitstellen
In einer Tabelle werden sowohl aktuelle Werte als auch Referenzwerte gespeichert. Verglichen wird immer der aktuelle Wert eines Testfalls mit seinem Referenzwert.
| TESTFALL_ID | DATUM | WERT | REFERENZ_JN |
|---|---|---|---|
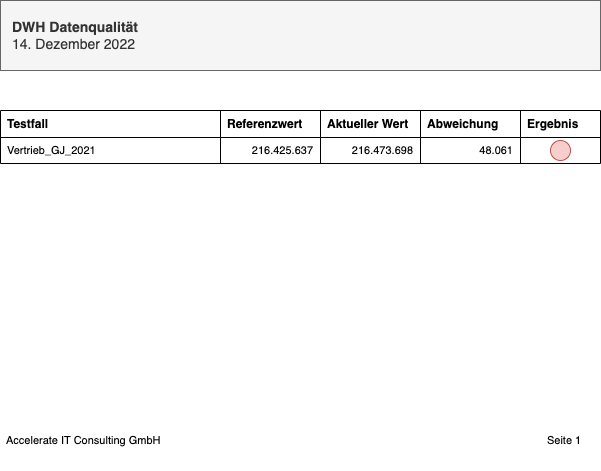
| Vertrieb_GJ_2021 | 06.04.2022 15:27:50 | 216.425.637 * | J |
| … | … | … | … |
| Vertrieb_GJ_2021 | 14.12.2022 05:30:44 | 216.473.698 ** | N |
* Referenzwert
** Aktueller Wert
![]() Die bereitgestellten Dateien werden nun in einem regelmäßigen automatischen Prozess verarbeitet. Das Ergebnis ist ein Bericht, der die Ergebnisse der Datenqualitätsprüfung für einen konfigurierbaren Empfängerkreis bereitstellt.
Die bereitgestellten Dateien werden nun in einem regelmäßigen automatischen Prozess verarbeitet. Das Ergebnis ist ein Bericht, der die Ergebnisse der Datenqualitätsprüfung für einen konfigurierbaren Empfängerkreis bereitstellt.
Beispielbericht Datenqualität
Technisch gesehen erfolgt das Einlesen der Quelldateien anhand von standardisierten Datenladeprozessen innerhalb eines ETL-Werkzeugs. Die Logik zur Überprüfung der bereitgestellten Werte befindet sich in SQLs. Die Ergebnisse werden in einer Data-Vault-Struktur in der Datenbank persistiert, sodass auch eine spätere Auswertung von vergangenen Datenqualitätsprüfungen möglich ist.
Die Methode wurde bewusst so konzipiert, dass sie unabhängig von einem Data Warehouse oder einem bestimmten ETL-Werkzeug angewendet werden kann. Sie ist ein Bestandteil unserer Business Intelligence Lösung businessNavi Professional.
Titelfoto: John Schnobrich / Unsplash